Key Features
CAIMAN-ASR enables at-scale automatic speech recognition (ASR), supporting up to 2000 real-time streams per accelerator card.
Lowest end-to-end latency
CAIMAN-ASR leverages the parallel processing advantages of Achronix’s Speedster7t® FPGA, the power behind the accelerator cards, to achieve extremely low latency inference. This enables NLP workloads to be performed in a human-like response time for end-to-end conversational AI.
Simple to integrate into existing systems
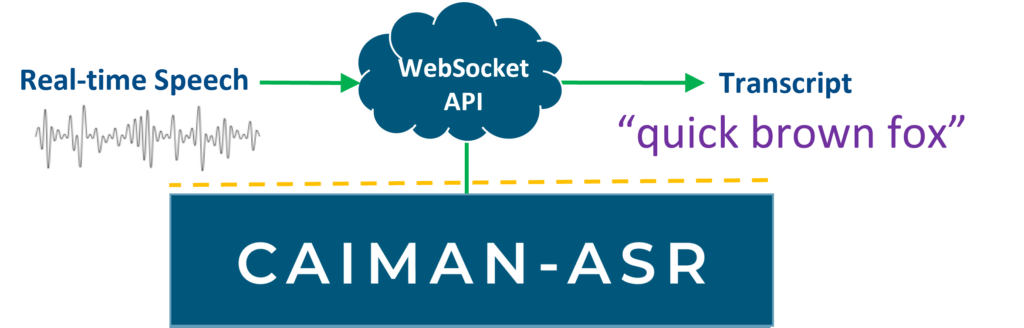
CAIMAN-ASR’s Websocket API can be easily connected to your service.
Scale up rapidly & easily
CAIMAN-ASR runs on industry-standard PCIe accelerator cards, enabling existing racks to be upgraded quickly for up to 20x greater call capacity. The VectorPath® S7t-VG6 accelerator card from BittWare is available off-the-shelf today.
Efficient inference, at scale
CAIMAN-ASR uses as much as 90% less energy to process the same number of real-time streams as an unaccelerated solution, significantly reducing energy costs and enhancing ESG (environmental, social, and governance) credentials.
Streaming transcription
CAIMAN-ASR is provided pre-trained for punctuated and cased English language transcription. For applications requiring specialist vocabularies or alternative languages, the neural model can easily be retrained with customers’ own bespoke datasets using the ML framework PyTorch.
Model Configurations
The solution supports two models: base and large of sizes 85M and 196M parameters respectively. These can be decoded with various configurations that trade off accuracy with latency and throughput. These trade-offs are described in more detail in the performance page but the ‘fastest’ and ‘most accurate’ configurations are summarized below:
| Description | Model | Parameters | Decoding | RTS | CL99 at max RTS | CL99 at RTS=32 | median UPL | HF Leaderboard WER |
|---|---|---|---|---|---|---|---|---|
| fastest | base | 85M | greedy | 2000 | 25 ms | 15 ms | 147 ms | 10.43% |
| most-accurate | large | 196M | beam, width=4 | 500 | 40 ms | 20 ms | 158 ms | 7.92% |
where:
- Realtime streams (RTS) is the number of concurrent streams that can be serviced by a single accelerator using default settings
- Compute latency 99th-percentile (CL99) is the 99th-percentile compute latency, which measures how long it takes for a model to make a prediction for one audio frame.
- User-perceived latency (UPL) is the time difference between when the user finishes saying a word and when it is returned as a transcript by the system.
- WER is the Word Error Rate, a measure of the accuracy of the model. Lower is better.
- HF Leaderboard WER is the WER of the model on the Huggingface Open ASR Leaderboard. WER is averaged across the test datasets.
The solution scales linearly up to 8 accelerators, and a single server has been measured to support 16000 RTS with the base model.