Introduction
CAIMAN-ASR provides high-throughput and low-latency automatic speech recognition (ASR).
This document outlines the following:
Installation
The latest release is available for download from https://github.com/MyrtleSoftware/caiman-asr/releases.
This provides the following package:
- ML training repo
- Live demo client
The following packages can be obtained by contacting Myrtle.ai at caiman-asr@myrtle.ai:
- CAIMAN-ASR server:
caiman-asr-server-<version>.run - CAIMAN-ASR demo:
caiman-asr-demo-<version>.run - Performance testing client:
caiman-asr-client-<version>.run - Model weights
A .run file is a self-extractable archive; download and execute it to extract the contents to the current directory.
Key Features
CAIMAN-ASR enables at-scale automatic speech recognition (ASR), supporting up to 2000 real-time streams per accelerator card.
Lowest end-to-end latency
CAIMAN-ASR leverages the parallel processing advantages of Achronix’s Speedster7t® FPGA, the power behind the accelerator cards, to achieve extremely low latency inference. This enables NLP workloads to be performed in a human-like response time for end-to-end conversational AI.
Simple to integrate into existing systems
CAIMAN-ASR's Websocket API can be easily connected to your service.
Scale up rapidly & easily
CAIMAN-ASR runs on industry-standard PCIe accelerator cards, enabling existing racks to be upgraded quickly for up to 20x greater call capacity. The VectorPath® S7t-VG6 accelerator card from BittWare is available off-the-shelf today.
Efficient inference, at scale
CAIMAN-ASR uses as much as 90% less energy to process the same number of real-time streams as an unaccelerated solution, significantly reducing energy costs and enhancing ESG (environmental, social, and governance) credentials.
Streaming transcription
CAIMAN-ASR is provided pre-trained for English language transcription. For applications requiring specialist vocabularies or alternative languages, the neural model can easily be retrained with customers’ own bespoke datasets using the ML framework PyTorch.
Model Configurations
The solution supports two models: base and large of sizes 85M and 196M parameters respectively. These can be decoded with various configurations that trade off accuracy with latency and throughput. These trade-offs are described in more detail in the performance page but the 'fastest' and 'most accurate' configurations are summarized below:
| Description | Model | Parameters | Decoding | Realtime streams (RTS) | p99 latency at max RTS | p99 latency at RTS=32 | Huggingface Leaderboard WER |
|---|---|---|---|---|---|---|---|
| fastest | base | 85M | greedy | 2000 | 25 ms | 15 ms | 13.50% |
| most-accurate | large | 196M | beam, width=4 | 500 | 40 ms | 20 ms | 11.59% |
where:
- Realtime streams (RTS) is the number of concurrent streams that can be serviced by a single accelerator using default settings
- p99 latency is the 99th-percentile latency to process a single 60 ms audio frame and return any predictions. Note that latency increases with the number of concurrent streams.
- WER is the Word Error Rate, a measure of the accuracy of the model. Lower is better.
- Huggingface Leaderboard WER is the WER of the model on the Huggingface Open ASR Leaderboard. WER is averaged across 8 test datasets.
The solution scales linearly up to 8 accelerators, and a single server has been measured to support 16000 RTS with the base model.
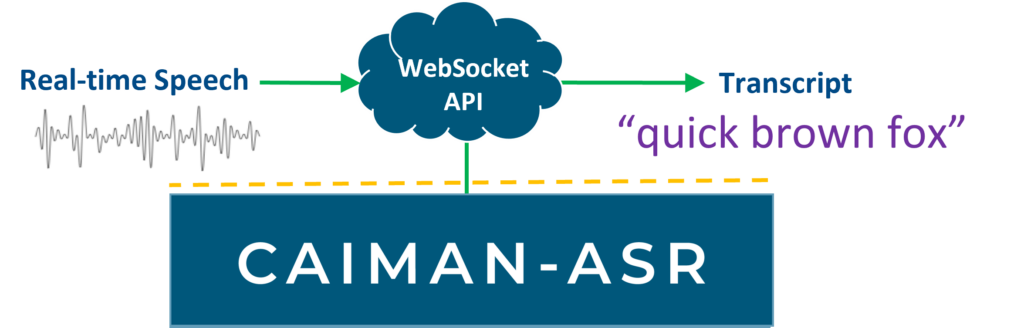
Product Overview
The CAIMAN-ASR solution is used via a websocket interface. Clients send audio data in chunks to the server, which returns transcriptions.
Components of the solution
-
CAIMAN-ASR bitstream: this is the bitstream that is flashed onto the FPGA. This bitstream supports all of the ML model architectures (for more details on the architectures, see the Models section). This only needs to be reprogrammed when a new update is released.
-
CAIMAN-ASR program: This contains the model weights and the instructions for a particular model architecture (e.g. base, large). It is loaded at runtime. The program is compiled from the
hardware-checkpointproduced during training. For more details on how to compile the CAIMAN-ASR program, see Compiling weights. Pre-trained weights are provided for English-language transcription for the base and large architectures. -
CAIMAN-ASR server: This provides a websocket interface for using the solution. It handles loading the program and communicating to and from the card. One server controls one card; if you have multiple cards, you can run multiple servers and use load-balancing.
-
ML training repository: This allows the user to train their own models, validate on their own data, and export model weights for the server.
An example configuration of CAIMAN-ASR is as follows:

Performance
The solution has various configurations that trade off accuracy and performance. In this page:
- Realtime streams (RTS) is the number of concurrent streams that can be serviced by a single accelerator using default settings
- p99 latency is the 99th-percentile latency to process a single 60 ms audio frame and return any predictions. Note that latency increases with the number of concurrent streams.
- WER is the Word Error Rate, a measure of the accuracy of the model. Lower is better.
- Huggingface Leaderboard WER is the WER of the model on the Huggingface Open ASR Leaderboard. WER is averaged across 8 test datasets.
The WERs in the following section are for models trained on 13k hours of open-source data described at the bottom of this page.
Beam search with n-gram LM
The solution supports decoding with a beam search (default beam width=4) with an n-gram language model for improved accuracy. The solution supports greedy decoding for higher throughput.
| Model | Parameters | Decoding | Realtime streams (RTS) | p99 latency at max RTS | Huggingface Leaderboard WER |
|---|---|---|---|---|---|
base | 85M | greedy | 2000 | 25 ms | 13.50% |
base | 85M | beam, width=4 | 1300 | 80 ms | 12.53% |
large | 196M | greedy | 800 | 25 ms | 12.44% |
large | 196M | beam, width=4 | 500 | 40 ms | 11.59% |
State resets
State resets is a technique that improves the accuracy on long utterances (over 60s) by resetting the model's hidden state after a fixed duration. This reduces the number of real-time streams that can be supported by around 25%:
| Model | Parameters | Decoding | Realtime streams (RTS) | p99 latency at max RTS | Huggingface Leaderboard WER |
|---|---|---|---|---|---|
base | 85M | greedy | 1600 | 45 ms | 13.47% |
base | 85M | beam, width=4 | 1200 | 50 ms | 12.53% |
large | 196M | greedy | 650 | 55 ms | 12.34% |
large | 196M | beam, width=4 | 400 | 60 ms | 11.55% |
Note that most of the data in the Huggingface leaderboard is less than 60s long so the impact of state resets is not reflected in the leaderboard WER.
13k hour dataset
The models above were trained on 13k hrs of open-source training data consisting of:
- LibriSpeech-960h
- Common Voice 17.0
- 961 hours from MLS
- Peoples' Speech: A ~9389 hour subset filtered for transcription quality
- 155 hrs of AMI
This data has a maximum_duration of 20s.
ML training flow
This document describes the flow of training the testing model on LibriSpeech.
This configuration is used as an example as it is quicker to train than either base or large.
Environment Setup
Clone the repo, build the image and set up the container with the appropriate volumes (as described here) with the following commands:
git clone https://github.com/MyrtleSoftware/caiman-asr.git && cd caiman-asr/training
./scripts/docker/build.sh
./scripts/docker/launch.sh <DATASETS> <CHECKPOINTS> <RESULTS>
Data Preparation
From inside the container, run the following command to download LibriSpeech, prepare JSON manifests, create a tokenizer, and a populated yaml configuration file.
SPM_SIZE=1023 CONFIG_NAME=testing-1023sp ./scripts/prepare_librispeech.sh
More details on preparing LibriSpeech into a JSON format can be found here.
Training
Modify <NUM_GPU> based on your machine and then run the following command to train a testing model.
A more detailed description of the training process can be found here.
./scripts/train.sh \
--data_dir /datasets/LibriSpeech \
--train_manifests librispeech-train-clean-100.json librispeech-train-clean-360.json librispeech-train-other-500.json \
--val_manifests librispeech-dev-clean.json \
--model_config configs/testing-1023sp_run.yaml \
--num_gpus <NUM_GPU> \
--global_batch_size 1008 \
--grad_accumulation_batches 42 \
--training_steps 42000
Validation
The following command will run the validation script and calculate the WER [%]. See here for more details.
./scripts/val.sh
Installation
These steps have been tested on Ubuntu 18.04, 20.04 and 22.04. Other Linux versions may work, since most processing takes place in a Docker container. However, the install_docker.sh script is currently specific to Ubuntu. Your machine does need NVIDIA GPU drivers installed. Your machine does NOT need CUDA installed.
- Clone the repository
git clone https://github.com/MyrtleSoftware/caiman-asr.git && cd caiman-asr
- Install Docker
source training/install_docker.sh
- Add your username to the docker group:
sudo usermod -a -G docker [user]
Run the following in the same terminal window, and you might not have to log out and in again:
newgrp docker
- Build the docker image
# Build from Dockerfile
cd training
./scripts/docker/build.sh
- Start an interactive session in the Docker container mounting the volumes, as described in the next section.
./scripts/docker/launch.sh <DATASETS> <CHECKPOINTS> <RESULTS>
Requirements
Currently, the reference uses CUDA-12.2. Here you can find a table listing compatible drivers: https://docs.nvidia.com/deploy/cuda-compatibility/index.html#binary-compatibility__table-toolkit-driver
Information about volume mounts
Setting up the training environment requires mounting the three directories:
<DATASETS>, <CHECKPOINTS>, and <RESULTS> for the training data, model checkpoints, and results, respectively.
The following table shows the mappings between directories on a host machine and inside the container.
| Host machine | Inside container |
|---|---|
| training | /workspace/training |
<DATASETS> | /datasets |
<CHECKPOINTS> | /checkpoints |
<RESULTS> | /results |
If your <DATASETS> directory contains symlinks to other drives (i.e. if your data is too large to fit on a single drive),
they will not be accessible from within the running container. In this case, you can pass the absolute paths to your drives
as the 4th, 5th, 6th, ... arguments to ./scripts/docker/launch.sh.
This will enable the container to follow symlinks to these drives.
During training, the model checkpoints are saved to the /results directory so it is sometimes convenient to
load them from /results rather than from /checkpoints.
Next Steps
Go to the Data preparation docs to see how to download and preprocess data in advance of training.
Model YAML configurations
Before training, you must select the model configuration you wish to train. Please refer to the key features for a description of the options available, as well as the training times. Having selected a configuration it is necessary to note the config path and sentencepiece vocabulary size ("spm size") of your chosen config from the following table as these will be needed in the subsequent data preparation steps:
| Name | Parameters | spm size | config | Acceleration supported? |
|---|---|---|---|---|
testing | 49M | 1023 | testing-1023sp.yaml | ✔ |
base | 85M | 8703 | base-8703sp.yaml | ✔ |
large | 196M | 17407 | large-17407sp.yaml | ✔ |
The testing configuration is included because it is quicker to train than either base or large. It is recommended to train the testing model on LibriSpeech as described here before training base or large on your own data.
The testing config is not recommended for production use.
Unlike the testing config, the base and large configs were optimized to provide a good tradeoff between WER and throughput on the accelerator.
The testing config will currently run on the accelerator, but this is deprecated.
Support for this may be removed in future releases.
Missing YAML fields
The configs referenced above are not intended to be edited directly. Instead, they are used as templates to create <config-name>_run.yaml files. The _run.yaml file is a copy of the chosen config with the following fields populated:
sentpiece_model: /datasets/sentencepieces/SENTENCEPIECE.modelstats_path: /datasets/stats/STATS_SUBDIRmax_duration: MAX_DURATIONngram_path: /datasets/ngrams/NGRAM_SUBDIR
Populating these fields can be performed by the training/scripts/create_config_set_env.sh script.
For example usage, see the following documentation: Prepare LibriSpeech in the JSON format.
Training times
Training throughputs on an 8 x A100 (80GB) system are as follows:
| Model | Training time | Throughput | No. of updates | grad_accumulation_batches | batch_split_factor |
|---|---|---|---|---|---|
base | 1.6 days | 729 utt/sec | 100k | 1 | 8 |
large | 2.2 days | 550 utt/sec | 100k | 1 | 16 |
Training times on an 8 x A5000 (24GB) system are as follows:
| Model | Training time | Throughput | No. of updates | grad_accumulation_batches | batch_split_factor |
|---|---|---|---|---|---|
base | 3.1 days | 379 utt/sec | 100k | 1 | 16 |
large | 8.5 days | 140 utt/sec | 100k | 8 | 4 |
where:
- Throughput is the number of utterances seen per second during training (higher is better)
- No. of updates is the number of optimiser steps at
--global_batch_size=1024that are required to train the models on the 50k hrs training dataset. You may need fewer steps when training with less data grad_accumulation_batchesis the number of gradient accumulation steps performed on each GPU before taking an optimizer stepbatch_split_factoris the number of sub-batches that thePER_GPU_BATCH_SIZEis split into before these sub-batches are passed through the joint network and loss.
For more details on these hyper-parameters, including how to set them, please refer to the batch size arguments documentation.
Data preparation
Having chosen which model configuration to train, you will need to complete the following preprocessing steps:
- Prepare your data in one of the supported training formats:
JSONorWebDataset. - Create a sentencepiece model from your training data.
- Record your training data log-mel stats for input feature normalization.
- Populate a YAML configuration file with the missing fields.
- Generate an n-gram language model from your training data.
Text normalization
The examples assume a character set of size 28: a space, an apostrophe and 26 lower case letters.
Transcripts will be normalized on the fly during training,
as set in the YAML config templates, normalize_transcripts: lowercase.
See Changing the character set
for how to configure the character set and normalization.
During validation, the predictions and reference transcripts
will be standardized.
See also
Supported Dataset Formats
CAIMAN-ASR supports reading data from four formats:
| Format | Modes | Description | Docs |
|---|---|---|---|
JSON | training + validation | All audio as wav or flac files in a single directory hierarchy with transcripts in json file(s) referencing these audio files. | [link] |
Webdataset | training + validation | Audio <key>.{flac,wav} files stored with associated <key>.txt transcripts in tar file shards. Format described here | [link] |
Directories | validation | Audio (wav or flac) files and the respective text transcripts are in two separate directories. | [link] |
Hugging Face | training (using provided conversion script) + validation | Hugging Face Hub datasets | [link] |
To train on your own proprietary dataset you will need to arrange for it to be in the WebDataset or JSON format.
A worked example of how to do this for the JSON format is provided in json_format.md.
The script hugging_face_to_json.py converts a Hugging Face dataset to the JSON format; see here for more details.
If you have a feature request to support training/validation on a different format, please open a GitHub issue.
JSON format
The JSON format is the default in this repository and if you are training on your own data it is recommended to manipulate it into this format. Note that the data preparation steps are slightly different given the model you have decided to train so please refer to the model configuration page first.
Page contents
Prepare LibriSpeech in JSON format
This page takes LibriSpeech as it is distributed from the https://www.openslr.org website and prepares it into a JSON manifest format.
Quick Start
To run the data preparation steps for LibriSpeech and the base model run the following from the training/ directory:
# Download data to /datasets/LibriSpeech: requires 120GB of disk
./scripts/prepare_librispeech.sh
To run preprocessing for the testing or large configurations, instead run:
SPM_SIZE=1023 CONFIG_NAME=testing-1023sp ./scripts/prepare_librispeech.sh
SPM_SIZE=17407 CONFIG_NAME=large-17407sp ./scripts/prepare_librispeech.sh
If ~/datasets on the host is mounted to /datasets, the downloaded data will be accessible outside the container at ~/datasets/LibriSpeech.
Further detail: prepare_librispeech.sh
The script will:
- Download data
- Create
JSONmanifests for each subset of LibriSpeech - Create a sentencepiece tokenizer from the train-960h subset
- Record log-mel stats for the train-960h subset
- Populate the missing fields of a YAML configuration template
- Generate an n-gram language model with KenLM from the train-960h subset
1. Data download
Having run the script, the following folders should exist inside the container:
/datasets/LibriSpeechtrain-clean-100/train-clean-360/train-other-500/dev-clean/dev-other/test-clean/test-other/
2. JSON manifests
/datasets/LibriSpeech/librispeech-train-clean-100.jsonlibrispeech-train-clean-360.jsonlibrispeech-train-other-500.jsonlibrispeech-dev-clean.jsonlibrispeech-dev-other.jsonlibrispeech-test-clean.jsonlibrispeech-test-other.json
3. Sentencepiece tokenizer
/datasets/sentencepieces/librispeech8703.modellibrispeech8703.vocab
4. Log-mel stats
/datasets/stats/STATS_SUBDIR:melmeans.ptmeln.ptmelvars.pt
The STATS_SUBDIR will differ depending on the model since these stats are affected by the feature extraction window size. They are:
testing:/datasets/stats/librispeech-winsz0.02- {
base,large}:/datasets/stats/librispeech-winsz0.025
5. _run.yaml config
In the configs/ directory. Depending on the model you are training you will have one of:
testing:configs/testing-1023sp_run.yamlbase:configs/base-8703sp_run.yamllarge:configs/large-17407sp_run.yaml
_run indicates that this is a complete config, not just a template.
6. N-gram language model
/datasets/ngrams/librispeech8703/transcripts.txtngram.arpangram.binary
To train an n-gram on a different dataset, see n-gram docs.
Prepare Other Datasets
Convert your dataset to the JSON format
Options:
- Adapt the code in
caiman_asr_train/data/make_datasets/librispeech.py. - If your dataset is in Hugging Face format, you can use the script described here
Generate artifacts needed for training
Suppose you have preprocessed CommonVoice, organized like this:
CommonVoice17.0
|-- common_voice_17.0_dev
|-- common_voice_17.0_dev.json
|-- common_voice_17.0_test
|-- common_voice_17.0_test.json
|-- common_voice_17.0_train
|-- common_voice_17.0_train.json
To generate the training artifacts, run the following:
DATASET_NAME_LOWER_CASE=commonvoice
MAX_DURATION_SECS=20.0
SPM_SIZE=8703
CONFIG_NAME=base-8703sp
DATA_DIR=/datasets/CommonVoice17.0
NGRAM_ORDER=4
TRAIN_MANIFESTS=/datasets/CommonVoice17.0/common_voice_17.0_train.json
./scripts/make_json_artifacts.sh $DATASET_NAME_LOWER_CASE $MAX_DURATION_SECS \
$SPM_SIZE $CONFIG_NAME $DATA_DIR $NGRAM_ORDER $TRAIN_MANIFESTS
where:
DATASET_NAME_LOWER_CASEwill determine the name of the generatedSENTENCEPIECEandSTATS_SUBDIRMAX_DURATION_SECSis number of seconds above which audio clips will be discarded during trainingSPM_SIZEis the size of the sentencepiece model---in this case, the base modelCONFIG_NAMEis the name of the template configuration file to readDATA_DIRis the path to your datasetNGRAM_ORDERis the order of the n-gram language model that can be used during beam searchTRAIN_MANIFESTScan be a space-separated list
It is advised that you use all of your training data transcripts to build the sentencepiece tokenizer but it is ok to use a subset of the data to calculate the mel stats via the --n_utterances_only flag to caiman_asr_train/data/generate_mel_stats.py.
Next steps
Having run the data preparation steps, go to the training docs to start training.
See also
WebDataset format
This page gives instructions to read training and validation data from the WebDataset format as opposed to the default JSON format described in the Data Formats documentation.
In the WebDataset format, <key>.{flac,wav} audio files are stored with associated <key>.txt transcripts in tar file shards. The tar file samples are read sequentially which increases I/O rates compared with random access.
Data Preparation
All commands in this README should be run from the training directory of the repo.
WebDataset building
If you would like to build your own WebDataset you should refer to the following resources:
- Script that converts from WeNet legacy format to WebDataset:
make_shard_list.py - Tutorial on creating WebDataset shards
At tarfile creation time, you must ensure that each audio file is stored sequentially with its associated .txt transcript file.
Text normalization
As discussed in more detail here it is necessary to normalize your transcripts so that they contain just spaces, apostrophes and lower-case letters. It is recommended to do this on the fly by setting normalize_transcripts: true in your config file. Another option is to perform this step offline when you create the WebDataset shards.
Data preparation: preprocess_webdataset.sh
In order to create the artefacts described in the data preparation intro, run the following inside a running container:
DATA_DIR=/datasets/TarredDataset TRAIN_TAR_FILES="train_*tar.tar" DATASET_NAME_LOWER_CASE=librispeech ./scripts/preprocess_webdataset.sh
This script accepts the following arguments:
DATA_DIR: Directory containing tar files.TRAIN_TAR_FILES: One or more shard file paths or globs.DATASET_NAME_LOWER_CASE: Name of dataset to use for naming sentencepiece model. Defaults tolibrispeech.MAX_DURATION_SECS: The maximum duration in seconds that you want to train on. Defaults to16.7as per LibriSpeech.CONFIG_NAME: Model name to use for the config from this table. Defaults tobase-8703sp.SPM_SIZE: Sentencepiece model size. Must matchCONFIG_NAME. Defaults to8703.NGRAM_ORDER: Order of n-gram language model. Defaults to 4.
Training and validation
To trigger training or validation for data stored in WebDataset format you should pass --read_from_tar to train.sh, val.sh.
You will also need to pass --val_tar_files (and for training, --train_tar_files) as one or more tar shard files/globs in --data_dir. For example if all of your training and tar files are in a flat --data_dir directory you might run:
./scripts/train.sh --read_from_tar --data_dir=/datasets/TarredDataset --train_tar_files train_*.tar --val_tar_files dev_*.tar
where {train,val}_tar_files can be one or more filenames or fileglobs. In this mode, your training and validation tar files must have non-overlapping names. Alternatively, if you have a nested file structure you can set --data_dir=/ and then pass absolute paths/globs to --train_tar_files and --val_tar_files for example like:
./scripts/train.sh --read_from_tar --data_dir=/ --train_tar_files /datasets/TarredDataset/train/** --val_tar_files /datasets/TarredDataset/dev/**
Note that in the second case (when paths are absolute), glob expansions will be performed by your shell rather than the WebDatasetReader class.
You should refer to the Training command documentation for more details on training arguments unrelated to this data format.
For validation you might run:
./scripts/val.sh --read_from_tar --data_dir=/datasets/TarredDataset --val_tar_files dev_*.tar
# or, absolute paths
./scripts/val.sh --read_from_tar --data_dir=/ --val_tar_files /datasets/TarredDataset/dev/**
WebDataset Limitations
Our WebDataset support currently has the following limitations:
- It isn't currently possible to mix and match
JSONandWebDatasetformats for the training and validation data passed to./scripts/train.sh. - It is necessary to have more shards per dataset (including validation data) than
num_gpusso that each GPU can read from a different shard.
Hugging Face Dataset Format
Validating directly on a dataset from the Hugging Face Hub
Validating on a Hugging Face dataset is supported in val.sh and train.sh.
To train on a Hugging Face dataset, you will need to convert it to JSON format,
as described in the next section.
This command will run validation on distil-whisper's version of LibriSpeech dev-other:
./scripts/val.sh --num_gpus 8 \
--checkpoint /path/to/checkpoint.pt \
--use_hugging_face \
--hugging_face_val_dataset distil-whisper/librispeech_asr \
--hugging_face_val_split validation.other
This will download the dataset and cache it in ~/.cache/huggingface, which will persist between containers.
Since datasets are large, you may wish to change the Hugging Face cache location via HF_CACHE=[path] ./scripts/docker/launch.sh ....
For some datasets, you may need to set more options. The following command will validate on the first 10 utterance of google/fleurs:
./scripts/val.sh --num_gpus 8 \
--checkpoint /path/to/checkpoint.pt \
--use_hugging_face \
--hugging_face_val_dataset google/fleurs \
--hugging_face_val_config en_us \
--hugging_face_val_transcript_key raw_transcription \
--hugging_face_val_split validation[0:10]
See the docstrings for more information.
Converting a Hugging Face dataset to JSON format
The following command will download the train.clean.100 split of
distil-whisper/librispeech_asr
and convert it to JSON format,
putting the result in /datasets/LibriSpeechHuggingFace:
python caiman_asr_train/data/make_datasets/hugging_face_to_json.py \
--hugging_face_dataset distil-whisper/librispeech_asr \
--data_dir /datasets/LibriSpeechHuggingFace \
--hugging_face_split train.clean.100
Directory of audio format
It is possible to run validation on all audio files (and their respective .txt transcripts)
found recursively in two directories --val_audio_dir and --val_txt_dir.
Directory Structure
The audio and transcripts directories should contain the same number of files, and the file names should match. For example, the structure of the directories could be:
audio_dir/
dir1/
file1.wav
file2.wav
txt_dir/
dir1/
file1.txt
file2.txt
The audio and transcript files can be under the same directory.
Running Validation
Using data from directories for validation can be done by parsing the argument
--val_from_dir along with the audio and transcript directories as follows:
scripts/val.sh --val_from_dir --val_audio_dir audio_dir --val_txt_dir txt_dir --dataset_dir /path/to/dataset/dir
where the audio_dir and txt_dir are relative to the --dataset_dir.
When training on webdataset files (--read_from_tar=True in the train.py), validation on directories is not supported.
Log-mel feature normalization
We normalize the acoustic log mel features based on the global mean and variance recorded over the training dataset.
Record dataset stats
The script generate_mel_stats.py computes these statistics
and stores them in /datasets/stats/<dataset_name+window_size> as PyTorch tensors. For example usage see:
scripts/make_json_artifacts.shscripts/preprocess_webdataset.sh
Training stability
Empirically, it was found that normalizing the input activations with dataset global mean and variance makes the early stage of training unstable.
As such, the default behaviour is to move between two modes of normalization on a schedule during training. This is handled by the MelFeatNormalizer class and explained in the docstring below:
class MelFeatNormalizer:
"""
Perform audio normalization, optionally blending between two normalization types.
The two types of normalization are:
1. use pre-computed NormType.DATASET_STATS per mel bin and normalize each
timestep independently
2. use utterance-specific NormType.UTTERANCE_STATS per mel bin that are
calculated over the time-dimension of the mel spectrogram
The first of these is used for validation/inference. The second method isn't
streaming compatible but is more stable during the early stages of training.
Therefore, by default, the training script blends between the two methods on a
schedule.
Validation
When running validation, the dataset global mean and variance are always used for normalization regardless of how far through the schedule the model is.
Backwards compatibility
Prior to v1.9.0, the per-utterance stats were used for normalization during training (and then streaming normalization was used during inference).
To evaluate a model trained on <=v1.8.0, use the --norm_over_utterance flag to the val.sh script.
Training
Training Command
Quick Start
This example demonstrates how to train a model on the LibriSpeech dataset using the testing model configuration.
This guide assumes that the user has followed the installation guide
and has prepared LibriSpeech according to the data preparation guide.
Selecting the batch size arguments is based on the machine specifications. More information on choosing them can be found here.
Recommendations for LibriSpeech training are:
- a global batch size of 1008 for a 24GB GPU
- use all
train-*subsets and validate ondev-clean - 42000 steps is sufficient for 960hrs of train data
- adjust number of GPUs using the
--num_gpus=<NUM_GPU>argument
To launch training inside the container, using a single GPU, run the following command:
./scripts/train.sh \
--data_dir=/datasets/LibriSpeech \
--train_manifests librispeech-train-clean-100.json librispeech-train-clean-360.json librispeech-train-other-500.json \
--val_manifests librispeech-dev-clean.json \
--model_config configs/testing-1023sp_run.yaml \
--num_gpus 1 \
--global_batch_size 1008 \
--grad_accumulation_batches 42 \
--training_steps 42000
The output of the training command is logged to /results/training_log_[timestamp].txt.
The arguments are logged to /results/training_args_[timestamp].json,
and the config file is saved to /results/[config file name]_[timestamp].yaml.
Defaults to update for your own data
When training on your own data you will need to change the following args from their defaults to reflect your setup:
--data_dir--train_manifests/--train_tar_files- To specify multiple training manifests, use
--train_manifestsfollowed by space-delimited file names, like this:--train_manifests first.json second.json third.json.
- To specify multiple training manifests, use
--val_manifests/--val_tar_files/(--val_audio_dir+--val_txt_dir)--model_config=configs/base-8703sp_run.yaml(or the_run.yamlconfig file created by yourscripts/preprocess_<your dataset>.shscript)
The audio paths stored in manifests are relative with respect to --data_dir. For example,
if your audio file path is train/1.flac and the data_dir is /datasets/LibriSpeech, then the dataloader
will try to load audio from /datasets/LibriSpeech/train/1.flac.
The learning-rate scheduler argument defaults are tested on 1k-50k hrs of data but when training on larger datasets than this you may need to tune the values. These arguments are:
--warmup_steps: number of steps over which learning rate is linearly increased from--min_learning_rate--hold_steps: number of steps over which the learning rate is kept constant after warmup--half_life_steps: the half life (in steps) for exponential learning rate decay
If you are using more than 50k hrs, it is recommended to start with half_life_steps=10880 and increase if necessary. Note that increasing
--half_life_steps increases the probability of diverging later in training.
Arguments
To resume training or fine tune a checkpoint see the documentation here.
The default setup saves an overwriting checkpoint every time the Word Error Rate (WER) improves on the dev set.
Also, a non-overwriting checkpoint is saved at the end of training.
By default, checkpoints are saved every 5000 steps, and the frequency can be changed by setting --save_frequency=N.
For a complete set of arguments and their respective docstrings see
args/train.py
and
args/shared.py.
Data Augmentation for Difficult Target Data
If you are targeting a production setting where background noise is common or audio arrives at 8kHZ, see here for guidelines.
Monitor training
To view the progress of your training you can use TensorBoard. See the TensorBoard documentation for more information of how to set up and use TensorBoard.
Profiling
To profile training, see these instructions.
Next Steps
Having trained a model:
- If you'd like to evaluate it on more test/validation data go to the validation docs.
- If you'd like to export a model checkpoint for inference go to the hardware export docs.
See also
Batch size hyperparameters
If you are training on an 8 x A100 (80GB) or 8 x A5000 (24GB) machine, the recommended batch size hyper-parameters are given here. Otherwise, this page gives guidance on how to select them. For a training command on num_gpus there are three command line args:
global_batch_sizegrad_accumulation_batchesbatch_split_factor
The Summary section at the bottom of this page describes how to select them. Before that, hyper-parameters and the motivation behind their selection are provided.
global_batch_size
This is the batch size seen by the model before taking an optimizer step.
RNN-T models require large global_batch_sizes in order to reach good WERs, but the larger the value, the longer training takes. The recommended value is --global_batch_size=1024 and many of the defaults in the repository (e.g. learning rate schedule) assume this value.
grad_accumulation_batches
This is the number of gradient accumulation steps performed on each GPU before taking an optimizer step. The actual PER_GPU_BATCH_SIZE is not controlled directly but can be calculated using the formula:
PER_GPU_BATCH_SIZE * grad_accumulation_batches * num_gpus = global_batch_size
The highest training throughput is achieved by using the highest PER_GPU_BATCH_SIZE (and lowest grad_accumulation_batches) possible without incurring an out-of-memory error (OOM) error.
Reducing grad_accumulation_batches will increase the training throughput but shouldn't have any affect on the WER.
batch_split_factor
The joint network output is a 4-dimensional tensor that requires a large amount of GPU VRAM. For the models in this repo, the maximum PER_GPU_JOINT_BATCH_SIZE is much lower than the maximum PER_GPU_BATCH_SIZE that can be run through the encoder and prediction networks without incurring an OOM. When PER_GPU_JOINT_BATCH_SIZE=PER_GPU_BATCH_SIZE, the GPU will be underutilised during the encoder and prediction forward and backwards passes which is important because these networks constitute the majority of the training-time compute.
The batch_split_factor arg makes it possible to increase the PER_GPU_BATCH_SIZE whilst keeping the PER_GPU_JOINT_BATCH_SIZE constant where:
PER_GPU_BATCH_SIZE / batch_split_factor = PER_GPU_JOINT_BATCH_SIZE
Starting from the default --batch_split_factor=1 it is usually possible to achieve higher throughputs by reducinggrad_accumulation_batches and increasing batch_split_factor while keeping their product constant.
Like with grad_accumulation_batches, changing batch_split_factor should not impact the WER.
Summary
In your training command it is recommended to:
- Set
--global_batch_size=1024 - Find the smallest possible
grad_accumulation_batchesthat will run without an OOM in the joint network or loss calculation - Then, progressively decrease
grad_accumulation_batchesand increasebatch_split_factorkeeping their product constant until you see an OOM in the encoder. Use the highestbatch_split_factorthat runs.
In order to test these, it is recommended to use your full training dataset as the utterance length distribution is important.
To check this quickly set --n_utterances_only=10000 in order to sample 10k utterances randomly from your data,
and --training_steps=20 in order to run 2 epochs (at the default --global_batch_size=1024).
When comparing throughputs it is better to compare the avg train utts/s from the second epoch as the first few iterations of the first epoch can be slow.
Special case: OOM in step 3
There is some constant VRAM overhead attached to batch splitting so for some machines, when you try step 3. above you will see OOMs. In this case you should:
- Take the
grad_accumulation_batchesfrom step 2. and increase by *=2 - Then perform step 3.
In this case it's not a given that your highest throughput setup with batch_split_factor > 1 will be higher than the throughput from step 2. with --batch_size-factor=1 so you should use whichever settings give a higher throughput.
TensorBoard
The training scripts write TensorBoard logs to /results during training.
To monitor training using TensorBoard, launch the port-forwarding TensorBoard container in another terminal:
./scripts/docker/launch_tb.sh <RESULTS> <OPTIONAL PORT NUMBER> <OPTIONAL NUM_SAMPLES>
If <OPTIONAL PORT NUMBER> isn't passed then it defaults to port 6010.
NUM_SAMPLES is the number of steps that TensorBoard will sample from the log and plot.
It defaults to 1000.
Then navigate to http://traininghostname:<OPTIONAL PORT NUMBER> in a web browser.
If a connection dies and you can't reconnect to your port because it's already allocated, run:
docker ps
docker stop <name of docker container with port forwarding>
Challenging target data
This page describes data augmentations that may help with these problems:
- Problem: Your target audio has non-speech background noise
- Solution: Train with background noise
- Problem: Speakers in your target audio talk over each other
- Solution: Train with babble noise
- Problem: Your target audio was recorded at 8 kHz, e.g. a narrowband telephone connection
- Solution: Train with narrowband conversion
Page contents
- Background Noise for training with background noise
- Babble Noise for training with babble noise
- Narrowband for training with narrowband conversion
- Inspecting Augmentations to listen to the effects of augmentations
- Random State Passing for training on long sequences
- Tokens Sampling for training with random tokens sampling
- Gradient Noise for training with gradient noise
Example Command
The following command will train the base model on the LibriSpeech dataset on an 8 x A100 (80GB) system with these settings:
- applying background noise to 25% of samples
- applying babble noise to 10% of samples
- downsampling 50% of samples to 8 kHz
- using the default noise schedule
- initial values 30–60dB
- noise delay of 4896 steps
- noise ramp of 4896 steps
./scripts/train.sh --model_config=configs/base-8703sp_run.yaml --num_gpus=8 \
--grad_accumulation_batches=1 --batch_split_factor=8 \
--training_steps=42000 --prob_background_noise=0.25 \
--prob_babble_noise=0.1 --prob_train_narrowband=0.5 \
--val_manifests=/datasets/LibriSpeech/librispeech-dev-other.json
These augmentations are applied independently, so some samples will have all augmentation types applied.
Background noise training
Background noise is set via the --prob_background_noise argument.
By default, prob_background_noise is 0.25.
Background noise takes a non-speech noise file and mixes it with the speech.
On an 8 x A100 (80GB) system, turning off background noise augmentation increases the base model's training throughput by ~17% and the large model's throughput by ~11%.
Implementation
The noise data is combined with speech data on-the-fly during training, using a
signal to noise ratio (SNR) randomly chosen between internal variables low and high.
The initial values for low and high can be specified (in dB) using the --noise_initial_low and
--noise_initial_high arguments when calling train.sh. This range is then maintained for the number of
steps specified by the --noise_delay_steps argument after which the noise level is ramped up over
--noise_ramp_steps to its final range.
The final range for background noise is 0–30dB (taken from the Google paper "Streaming
end-to-end speech recognition for mobile devices", He et al., 2018).
Before combination, the noise audio will be duplicated to become at least as long as the speech utterance.
Background noise dataset
By default, background noise will use Myrtle/CAIMAN-ASR-BackgroundNoise from the Hugging Face Hub.
Note that this dataset will be cached in ~/.cache/huggingface/ in order to persist between containers.
You can change this location like so: HF_CACHE=[path] ./scripts/docker/launch.sh ....
To change the default noise dataset, set --noise_dataset to an audio dataset on the Hugging Face Hub.
The training script will use all the audios in the noise dataset's train split.
If you instead wish to train with local noise files, make sure your noise is organized in the Hugging Face AudioFolder format.
Then set --noise_dataset to be the path to the directory containing your noise data (i.e. the parent of the data directory), and pass --use_noise_audio_folder.
Babble noise training
Babble noise is set via the --prob_babble_noise argument.
By default, prob_babble_noise is 0.0.
Babble is applied by taking other utterances from the same batch and mixing them with the speech.
Implementation
Babble noise is combined with speech in the same way that background noise is.
The --noise_initial_low, --noise_initial_high, --noise_delay_steps, and --noise_ramp_steps
arguments are shared between background noise and babble noise.
The only difference is that the final range of babble noise is 15–30dB.
Narrowband training
For some target domains, data is recorded at (or compressed to) 8 kHz (narrowband). For models trained with audio >8 kHz (16 kHz is the default) the audio will be upsampled to the higher sample rate before inference. This creates a mismatch between training and inference, since the model will partly rely on information from the higher frequency bands.
This can be partly mitigated by resampling a part of the training data to narrowband and back to higher frequencies, so the model is trained on audio that more closely resembles the validation data.
To apply this downsampling on-the-fly to a random half of batches, set --prob_train_narrowband=0.5 in your training command.
Inspecting augmentations
To listen to the effects of augmentations, pass --inspect_audio. All audios will then be saved to /results/augmented_audios after augmentations have been applied. This is intended for debugging only—DALI is slower with this option, and a full epoch of saved audios will use as much disk space as the training dataset.
Random State Passing
RNN-Ts can find it difficult to generalise to sequences longer than those seen during training, as described in Chiu et al, 2020.
Random State Passing (RSP) (Narayanan et al., 2019) reduces this issue by simulating longer sequences during training. It does this by initialising the model with states from the previous batch with some probability. On in-house validation data, this reduces WERs on long (~1 hour) utterances by roughly 40% relative.
Further details
Experiments indicated:
- It was better to apply RSP 1% of the time, instead of 50% as in the paper.
- Applying RSP from the beginning of training raised WERs, so RSP is only applied after
--rsp_delaysteps--rsp_delaycan be set on the command line but, by default, is set to the step at which the learning rate has decayed to 1/8 of its initial value (i.e. after x3half_life_stepshave elapsed). To see the benefits from RSP, it is recommended that >=5k updates are done after the RSP is switched on, so this heuristic will not be appropriate if you intend to cancel training much sooner than this. See docstring ofset_rsp_delay_defaultfunction for more details.
RSP is on by default, and can be modified via the --rsp_seq_len_freq argument, e.g. --rsp_seq_len_freq 99 0 1.
This parameter controls RSP's frequency and amount; see the --rsp_seq_len_freq docstring in args/train.py.
RSP requires Myrtle.ai's custom LSTM which is why custom_lstm: true is set by default in the yaml configs.
See also
RSP is applied at training-time. An inference-time feature, state resets can be used in conjunction with RSP to further reduce WERs on long utterances.
Tokens Sampling
Text needs to be in the form of tokens before it is processed by the RNNT. These tokens can represent words, characters, or subwords. CAIMAN-ASR uses subwords which are formed out of 28 characters, namely the lower-case english alphabet letters, along with the space and apostrophe characters. The tokens are derived from the tokenizer model SentencePiece. A SentencePiece tokenizer model can be trained on raw text, and produces a vocabulary with the most probable subwords that emerge in the text. These derived vocabulary entries (i.e. the tokens) are scored according to the (negative log) probability of occurring in the text that the tokenizer was trained on. The tokenizer entries include all the individual characters of the text, in order to avoid out-of-vocabulary error when tokenizing any text. When using the tokenizer model to convert text into tokens the user has the option of tokenizing not with the most probable tokens (subwords), but with a combination of tokens that have lower score.
Utilising the random tokens sampling is a form of data augmentation and it is applied on a percentage of the training data, and not on the validation data. This can be done with setting the sampling parameter into a real value in the range [0.0, 1.0] in the configuration file, e.g.:
sampling: 0.05
A value of 0.05 (default) means that 5% of the training data will be tokenized with random tokens sampling. A value of 0.0 means no use of tokens sampling, whereas a value of 1.0 applies random tokens sampling in the whole text.
Gradient Noise
Adding Gaussian noise to the network gradients improves generalization to out-of-domain datasets by not over-fitting on the datasets it is trained on. Inspired by the research paper by Neelakantan et. al., the noise level is sampled from a Gaussian distribution with \(mean=0.0\) and standard deviation that decays according to the following formula:
$$ \sigma(t)=\frac{noise}{{(1 + t - t_{start})}^{decay}}, $$
\(noise\) is the initial noise level, \(decay=0.55\) is the decay constant, \(t\) is the step, and \(t_{start}\) is the step when the gradient noise is switched on.
Training with gradient noise is switched off by default. It can be switched on by setting the noise level to be a positive value in the config file.
Experiments indicate that the best time to switch on the gradient noise is after the warm-up period
(i.e. after warmup_steps). Moreover, the noise is only added in the gradients of the encoder components,
hence if during training the user chooses to freeze the encoder, adding gradient noise will be off by default.
Resuming and Fine-tuning
The --resume option to the train.sh script enables you to resume training from a --checkpoint=/path/to/checkpoint.pt
file including the optimizer state.
Resuming from a checkpoint will continue training from the last step recorded in the checkpoint, and the files that will be seen by
the model will be the ones that would be seen if the model training was not interrupted.
In the case of resuming training when using tar files, the order of the files that will be seen by the model is the same as the order that the model saw when
the training started from scratch, i.e. not the same as if training had not been interrupted.
The --fine_tune option ensures that training starts anew, with a new learning rate schedule and optimizer state from the specified checkpoint.
To freeze the encoder weights during training change the enc_freeze option in the config file to:
enc_freeze: true
Profiling
You can turn on profiling by passing --profiler in your training or validation command. Note that profiling will likely slow down the script and is intended as a debugging feature.
Some of the profiling results are only saved after the script completes so it is necessary to avoid killing with Ctrl + C if you want to record the full profiling results.
As such, when profiling training it is recommended to:
- profile a small number of
--training_steps - set
--n_utterances_only [N_UTTERANCES_ONLY]to sample from the training dataset.
Similarly, when profiling validation it is recommended to use --nth_batch_only=<batch idx>
Profiling results will be saved in [output_dir]/benchmark/. This consists of:
-
yappi logs named
program[rank]_[timestamp].prof. These can be viewed via SnakeViz:Launch a container with the command
SNAKEVIZ_PORT=[an unused port] ./scripts/docker/launch.sh .... Inside the container, run./scripts/profile/launch_snakeviz.bash /results/benchmark/program[rank]_[timestamp].profThis will print an interactive URL that you can view in a web browser.
-
top logs named
top_log_[timestamp].html. These can be viewed outside the container using a web browser. -
nvidia-smi text logs named
nvidia_smi_log_[timestamp].txt. -
Manual timings of certain parts of the training loop for each training step constituting an epoch. These are text files named
timings_stepN_rankM_[timestamp].txt. -
system information in
system_info_[timestamp].txt.
Sending results
In order to share debug information with Myrtle.ai please run the following script:
OUTPUT_DIR=/<results dir to share> TAR_FILE=logs_to_share.tar.gz ./scripts/tar_logs_exclude_ckpts.bash
This will compress the logs excluding any checkpoints present in OUTPUT_DIR. The resulting logs_to_share.tar.gz file can be shared with Myrtle.ai or another third-party.
Changing the character set
With default training settings, the CAIMAN-ASR model will only output
lowercase ASCII characters, space, and '.
This page describes how to change the settings to support additional characters
or different languages.
The code has been tested with English language training, but it provides basic support for other languages. If you would like additional support for a specific language, please contact caiman-asr@myrtle.ai
Guidelines
Step 1: Choose a character set
As described above, the default character set is abcdefghijklmnopqrstuvwxyz '.
The maximum size of your character set is the sentencepiece vocabulary size, as each character in the character set receives a unique token in the sentencepiece vocabulary. See here for the vocabulary size for each model configuration.
We recommend keeping the character set at least an order of magnitude smaller than the sentencepiece vocabulary size. Otherwise there may be too few multi-character subwords in the vocabulary, which might make the model less effective.
Step 2: Choose a normalizer
It's possible for the raw training data to contain characters other than those in the character set. For instance, an English dataset might contain "café", even if the character set is only ASCII.
To handle these rare characters, you can select a normalizer in the yaml config file. The options, in order of least to most interference, are:
identity- Does not transform the input text
scrub- Removes characters that are not in the config file's character set
- Recommended for languages that use a character set different than ASCII
ascii- Replaces non-ASCII characters with ASCII equivalents
- For example, "café" becomes "cafe"
- Recommended if model is predicting English with digits
- Also applies
scrub
digit_to_word- Replaces digits with their word equivalents
- For example, "123rd" becomes "one hundred and twenty-third"
- Assumes English names for numbers
- Also applies
asciiandscrub
lowercase- Lowercases text and expands abbreviations
- For example, "Mr." becomes "mister"
- This is the default normalizer
- Recommended for predicting lowercase English without digits
- Also applies
digit_to_word,ascii, andscrub
Step 3: Custom replacements
You may want to tweak how text is normalized, beyond the five normalizers listed above. For example, you might want to make the following changes to your training transcripts:
- Replace ";" with ","
- Replace "-" with " " if normalization is on and "-" isn't in your character set, so that "twenty-one" becomes "twenty one" instead of "twentyone"
You can make these changes by adding custom replacement instructions to the yaml file. Example:
replacements:
- old: ";"
new: ","
- old: "-"
new: " "
In the normalization pipeline, these replacements will be applied
just before the transcripts are scrubbed of characters not in the character set.
The replacements will still be applied even if the normalizer is identity,
although by default there are no replacements.
Step 4: Tag removal
Some datasets contain tags, such as <silence> or <affirmative>.
By default, these tags are removed from the training transcripts
during on-the-fly text normalization, before the text is tokenized.
Hence the model will not predict these tags during inference.
If you want the model to be trained with tags
and possibly predict tags during inference,
set remove_tags: false in the yaml file.
If you set remove_tags: false
but do not train your tokenizer on a dataset with tags,
the tokenizer will crash
if it sees tags during model training or validation.
Step 5: Update fields in the model configuration
You'll want to update:
- the character set under
labelsto your custom character set - the normalizer under
normalize_transcripts - the replacements under
replacements - Whether to remove tags, under
remove_tags
Step 6: Train a sentencepiece model
The following command is used to train the Librispeech sentencepiece model using the default character set, as happens here:
python caiman_asr_train/data/spm/spm_from_json.py --spm_size "$SPM_SIZE" \
--spm_name "$SPM_NAME" --data_dir "$DATA_DIR" \
--train_manifests $TRAIN_MANIFESTS \
--output_dir /datasets/sentencepieces \
--model_config "$RUN_CONFIG"
This script reads the config file, so it will train the correct sentencepiece model for your character set, normalizer, and replacements.
You may also wish to run some other scripts in
scripts/make_json_artifacts.sh,
such as the scripts that prepare the LM data
and train the n-gram LM using your new tokenizer.
Step 7: Finish filling out the model configuration
If you haven't filled out the standard
missing fields
in the yaml config file, be sure to update them,
especially the sentpiece_model you trained in Step 6.
Inspecting character errors
By default, the WER calculation
ignores capitalization or punctuation errors.
If you would like to see an analysis of these errors,
you can use the flag --breakdown_wer.
Validation
Validation Command
Quick Start
To run validation, execute:
./scripts/val.sh
By default, a checkpoint saved at /results/RNN-T_best_checkpoint.pt, with the testing-1023sp_run.yaml model config, is evaluated on the /datasets/LibriSpeech/librispeech-dev-clean.json manifest.
Arguments
Customise validation by specifying the --checkpoint, --model_config, and --val_manifests arguments to adjust the model checkpoint, model YAML configuration, and validation manifest file(s), respectively.
To save the predictions, pass --dump_preds as described here.
See args/val.py and
args/shared.py
for the complete set of arguments and their respective docstrings.
Further Detail
- All references and hypotheses are normalized with the Whisper normalizer before calculating WERs, as described in the WER calculation docs. To switch off normalization, modify the respective config file entry to read
standardize_wer: false. - During validation the state resets technique is applied by default in order to increase the model's accuracy.
- The model's accuracy can be improved by using beam search and an n-gram language model.
- Validating on long utterances is calibrated to not run out of memory on a single 11 GB GPU. If a smaller GPU is used, or utterances are longer than 2 hours, refer to this document.
Next Step
See the hardware export documentation for instructions on exporting a hardware checkpoint for inference on an accelerator.
WER Calculation
WER Formula
Word Error Rate (WER) is a metric commonly used for measuring the performance of Automatic Speech Recognition (ASR) systems.
It compares the hypothesis transcript generated by the model with the reference transcript, which is considered to be the ground truth. The metric measures the minimum number of words that have to either be substituted, removed, or inserted in the hypothesis text in order to match the reference text.
For example:
Hypothesis: the cat and the brown dogs sat on the long bench
Reference: the black cat and the brown dog sat on the bench
In the hypothesis there are:
- 1 deletion error (word "black"),
- 1 substitution error ("dogs" instead of "dog"), and
- 1 insertion error (word "long"), in a total of 11 words in the reference text.
The WER for this transcription is:
$$ WER = \frac{S + D + I}{N} \times 100 = \frac{1 + 1 + 1}{11} \times 100=27.27\% $$
WER Standardization
Before the calculation of the WER, when standardize_wer: true in the yaml config,
the text of both hypotheses and references is standardized, so that the model accuracy is
not penalised for mistakes due to differences in capitalisation, punctuation, etc.
Currently, CAIMAN-ASR uses the Whisper EnglishSpellingNormalizer. The Whisper standardization rules applied are the following:
- Remove text between brackets (
< >or[ ]). - Remove punctuation (parentheses, commas, periods etc).
- Remove filler words like hmm, uh, etc.
- Substitute contractions with full words, e.g. won't -> will not.
- Convert British into American English spelling, e.g. standardise -> standardize. The list of words are included in the file english.json
We additionally apply the following transformations:
- Remove diacritics ("café" becomes "cafe")
- Lowercase the text
- Expand digits and symbols into words ("$1.02" becomes "one dollar two cents", "cats & dogs" becomes "cats and dogs")
- Expand common abbreviations ("Dr. Smith" becomes "doctor smith")
For example:
Hypothesis: that's what we'll standardise in today's example
Reference: hmm that is what we'll standardize in today's example
After applying the Whisper standardization rules, the sentences are formed:
Hypothesis: that is what we will standardize in today's example
Reference: that is what we will standardize in today's example
Which are identical, hence the WER=0%.
State Resets
State Resets is a streaming-compatible version of the 'Dynamic Overlapping Inference' proposed in this paper. It is a technique that can be used during inference, where the hidden state of the model is reset after a fixed duration. This is achieved by splitting long utterances into shorter segments, and evaluating each segment independently of the previous ones.
State Resets can be amended to include an overlapping region, where each of the segments have prepended audio from their previous segments. The overlapping region of the next segment is used as a warm-up for the decoder between the state resets and tokens emitted in the overlapping region are always from the first segment.
Evaluation with State Resets is on by default, with the following arguments:
--sr_segment=15 --sr_overlap=3
With these arguments, the utterances longer than 15 seconds will be split into segments of 15 seconds each, where, other than the first segment, all segments include the final 3 seconds of the previous segment.
Experiments indicate that the above defaults show a 10% relative reduction in the WER for long-utterances, and do not deteriorate the short utterance performance.
To turn off state resets, set --sr_segment=0.
In order to use state resets it is required that the --val_batch_size is kept to the default value of 1.
At inference time
The user can configure whether to use state resets on the CAIMAN-ASR server. More information can be found here.
See also
State resets is applied at inference-time. A training-time feature, RSP can be used in conjunction with state-resets to further reduce WERs on long utterances.
Beam search decoder
By default validation is carried out using a greedy decoder. To instead use a beam decoder, run
./scripts/val.sh --decoder=beam
which runs with a default beam width of 4. To change the beam width, run, for example
./scripts/val.sh --decoder=beam --beam_width=8
All of the beam decoder options described in this page are available in train.sh as well as val.sh.
Adaptive beam search
The beam decoder utilises an optimised version of beam search - adaptive beam search - which reduces decoding compute by reducing the number of beam expansions to consider, without degrading WER. Two hypothesis pruning methods are employed:
- Hypotheses with a score less than
beam_prune_score_thresh(default 0.4) below the best hypothesis' score are pruned. - Tokens with a logprob score less than
beam_prune_topk_thresh(default 1.5) below the most likely token are ignored.
Reducing beam_prune_score_thresh and beam_prune_topk_thresh increases pruning aggressiveness; setting them < 0 disables pruning.
Adaptive beam search dynamically adjusts computation based on model confidence, using more compute when uncertain and behaving almost greedily when confident.
Softmax temperature
The beam decoder applies a softmax temperature to the logits. By default the --temperature=1.4 as this was found to improve WER across a range of configurations. Increasing the temperature will increase the beam diversity and make the greedy path less likely.
Fuzzy top-k logits
When using --decoder=beam, the model first calculates the logits for all classes (or tokens),
applies the log-softmax function to get log probabilities, and then selects the top beam-width
tokens to expand the beam.
However, in the hardware-accelerated solution, the I/O of sending the full vocab-size logits tensor from the FPGA to the CPU is a bottleneck. To address this, the hardware-accelerated solution sends a reduced set of logits to the CPU. Specifically, it sends the highest-value logits within some local block of the logits tensor. This enables a 'fuzzy top-k' operation which is approximate to the full top-k operation with some small difference.
Our experiments show that using the reduced logits tensor (fuzzy top-k logits) does not impact the model's WER performance.
Using fuzzy top-k logits
To use a reduced tensor implementation similar to the accelerated version, run the following command:
./scripts/val.sh --num_gpus=2 --decoder=beam --fuzzy_topk_logits
Please note that the evaluation time will increase by ~30% compared to standard beam search, so it is disabled by default.
N-gram language models
N-gram language models are used with beam decoding to improve WER. This is on by default and described in more detail in the N-gram language model documentation.
N-gram Language Model
An external language model can improve ASR accuracy, especially in out-of-domain contexts with rare or specialised vocabulary.
CAIMAN-ASR supports the use of KenLM n-gram language model shallow fusion corrections when using --decoder=beam.
We have seen a consistent WER improvement even when the N-gram is trained on ASR data transcripts.
As such we automatically generate this N-gram during preprocessing and use it during validation by default.
See the Validation with an N-gram section for more details.
Build an N-gram Language Model
When adapting the preprocessing steps detailed here for your own dataset, you should have generated an n-gram language model trained on your transcripts. To generate an n-gram from a different dataset, see the following steps.
Preparing Data
To train an n-gram with KenLM on transcripts from ASR datasets, the data must first be prepared into the correct format - a .txt file where tokens within a sentence are space-separated and each sentence appears on a new line.
To gather the transcripts from json manifest files, run the following command inside a running container:
python caiman_asr_train/lm/prep_kenlm_data.py --data_dir /path/to/dataset/ --manifests manifest1.json manifest2.json --output_path /path/to/transcripts.txt --model_config configs/config.yaml
To instead gather the transcripts from data in the WebDataset format, run the following command:
python caiman_asr_train/lm/prep_kenlm_data.py --data_dir /path/to/dataset/ --read_from_tar --tar_files file1.tar file2.tar --output_path /path/to/transcripts.txt --model_config configs/config.yaml
Use the same model configuration file that was used for RNN-T. If the n-gram is not trained on data tokenized by the same SentencePiece model, using an ngram language model is likely to degrade WER.
Training an N-gram
To train an n-gram, run the generate_ngram.sh script as follows:
./scripts/generate_ngram.sh [NGRAM_ORDER] /path/to/transcripts.txt /path/to/ngram.arpa /path/to/ngram.binary
For example, to generate a 4-gram, set [NGRAM_ORDER] to 4 as follows:
./scripts/generate_ngram.sh 4 /path/to/transcripts.txt /path/to/ngram.arpa /path/to/ngram.binary
The script will produce an ARPA file, which is a human-readable version of the language model, and a binary file, which allows for faster loading and is the recommended format. Binary files are the only usable format when generating hardware checkpoints, though providing an n-gram is optional.
Validation with an N-gram
During beam search validation, the n-gram language model generated during preprocessing is used by default, by reading from the following entries in the model configuration file:
ngram:
ngram_path: /datasets/ngrams/NGRAM_SUBDIR
scale_factor: 0.05
First, a binary file, named ngram.binary, in NGRAM_SUBDIR is searched for. If not found, an ARPA file - ngram.arpa - is searched for. If neither file exists, the process will crash with an error. To prevent this, use the --skip_ngram flag to disable the use of an n-gram during validation with beam search:
scripts/val.sh --decoder=beam --skip_ngram
The scale_factor adjusts the scores from the n-gram language model, and this will require tuning for your dataset. Values between 0.05 and 0.1 are empirically effective for improving WER. See the Sweep Scale Factor section below for details on running a sweep across the scale factor.
To use an n-gram that was trained on a different dataset, use the --override_ngram_path argument, which will take precedence over any n-grams in NGRAM_SUBDIR:
scripts/val.sh --decoder=beam --override_ngram_path /path/to/ngram.binary
Sweep Scale Factor
To optimize the scale_factor for your n-gram language model, use the sweep_scale_factor.py script.
This script iterates over multiple scale_factor values, performs validation, and updates your model config YAML with the best one based on WER.
Run the following command to perform a sweep:
python caiman_asr_train/lm/sweep_scale_factor.py --checkpoint /path/to/checkpoint.pt --model_config configs/config.yaml --val_manifests /path/to/manifest.json
By default, a sweep is performed across [0.01, 0.025, 0.05, 0.075, 0.1, 0.15, 0.2, 0.25].
To specify custom values, use the --scale_factors argument:
python caiman_asr_train/lm/sweep_scale_factor.py --scale_factors 0.1 0.2 0.3 --checkpoint /path/to/checkpoint.pt --model_config configs/config.yaml --val_manifests /path/to/manifest.json
Automatic batch size reduction
When validating on long utterances with the large model, the encoder may run out of memory even with a batch size of 1.
State resets are implemented by splitting one utterance into a batch
of smaller utterances, even when --val_batch_size=1.
This creates an opportunity to reduce the VRAM usage
further, by processing the 'batch' created from one long utterance in smaller
batches, instead of all at once.
The validation script will automatically reduce the batch size if the number
of inputs to the encoder is greater than --max_inputs_per_batch. The default
value of --max_inputs_per_batch is 1e7, which was calibrated to let the
large model validate on a 2-hour-long utterance on an 11 GB GPU.
Note that this option can't reduce memory usage on a long utterance if state resets is turned off, since the batch size can't go below 1.
You may wish to reduce the default --max_inputs_per_batch if you have a smaller GPU/longer utterances.
Increasing the default is probably unnecessary, since validation on an 8 x A100 (80GB) system
is not slowed down by the default --max_inputs_per_batch.
Saving Predictions
To dump the predicted text for a list of input wav files, pass the --dump_preds argument and call val.sh:
./scripts/val.sh --dump_preds --val_manifests=/results/your-inference-list.json
Predicted text will be written to /results/preds[rank].txt
The argument --dump_preds can be used whether or not there are ground-truth transcripts in the json file. If there are,
then the word error rate reported by val will be accurate; if not, then it will be nonsense and should
be ignored. The minimal json file for inference (with 2 wav files) looks like this:
[
{
"transcript": "dummy",
"files": [
{
"fname": "relative-path/to/stem1.wav"
}
],
"original_duration": 0.0
},
{
"transcript": "dummy",
"files": [
{
"fname": "relative-path/to/stem2.wav"
}
],
"original_duration": 0.0
}
]
where "dummy" can be replaced by the ground-truth transcript for accurate word error rate calculation,
where the filenames are relative to the --data_dir argument fed to (or defaulted to by) val.sh, and where
the original_duration values are effectively ignored (compared to infinity) but must be present.
Predictions can be generated using other checkpoints by specifying the --checkpoint argument.
Export inference checkpoint
To run your model on Myrtle.ai's hardware-accelerated inference server you will need to create a hardware checkpoint to enable transfer of this and other data.
This requires mel-bin mean and variances as described here.
To create a hardware checkpoint run:
python ./caiman_asr_train/export/hardware_ckpt.py \
--ckpt /results/RNN-T_best_checkpoint.pt \
--config <path/to/config.yaml> \
--output_ckpt /results/hardware_checkpoint.testing.example.pt
where /results/RNN-T_best_checkpoint.pt is your best checkpoint.
The script should take a few seconds to run.
The generated hardware checkpoint will contain the sentencepiece model specified in the config file and the dataset mel stats.
The hardware checkpoint will also include the binary n-gram generated during preprocessing, as specified by the ngram_path field in the config file.
However, this is optional, and can be skipped by passing the --skip_ngram flag:
python ./caiman_asr_train/export/hardware_ckpt.py \
--ckpt /results/RNN-T_best_checkpoint.pt \
--config <path/to/config.yaml> \
--output_ckpt /results/hardware_checkpoint.testing.example.pt
--skip_ngram
To include an n-gram that was generated on a different dataset, use the --override_ngram_path argument:
python ./caiman_asr_train/export/hardware_ckpt.py \
--ckpt /results/RNN-T_best_checkpoint.pt \
--config <path/to/config.yaml> \
--output_ckpt /results/hardware_checkpoint.testing.example.pt \
--override_ngram_path /path/to/ngram.binary
Inference flow
The CAIMAN-ASR server provides low-latency, real-time streaming ASR workloads behind a convenient WebSocket API. This section describes how to set up the CAIMAN-ASR server for inference.
To use the inference you need to obtain a license, program the FPGA and then run the server docker image (or the demo image for a quick start).
Licensing
Licenses are required for each FPGA, and each license is tied to a particular FPGA's unique identifier. Licenses may also have a maximum version number and release date that they support. Additional or replacement licenses can be purchased by contacting Myrtle.ai or Achronix.
The CAIMAN-ASR server can run in "CPU mode", where the FPGA is not used and all inference is done on the CPU. This does not require a license and is useful for testing; however the throughput of the CPU is much lower. For details of how to run this, see the CAIMAN-ASR server documentation.
The directory containing the license file(s) is passed as an argument to the start_server script.
Programming the Achronix Speedster7t FPGA
The bitstream that goes on the FPGA supports all the model architectures, and it only needs to be reprogrammed when Myrtle.ai releases an updated bitstream. If you have received a demo system from Achronix or Myrtle.ai then the bitstream will likely already have been set up for you and you will not need to follow this step.
Checking that the card has enumerated
You can check if the card has enumerated properly if lspci lists any devices with ID 12ba:0069
$ lspci -d 12ba:0069
25:00.0 Non-Essential Instrumentation [1300]: BittWare, Inc. Device 0069 (rev 01)
There should be a result for each card. If the card has not enumerated properly, you may need to power cycle the machine.
Flashing via JTAG
The board needs to have a JTAG cable connected to enable it to be flashed. See the VectorPath documentation for more information on how to connect the JTAG cable.
You also need to have the Achronix ACE software installed on the machine. To acquire the Achronix tool suite, please contact Achronix support. A license is not required, as "lab mode" is sufficient for flashing the FPGA.
Enter the ACE console:
sudo rlwrap /opt/ACE_9.1.1/Achronix-linux/ace -lab_mode -batch
Then run the following command:
jtag::get_connected_devices
This will list the devices connected via JTAG. As above, there should be one device ID for each card. If you have multiple devices connected you will need to repeat the programming step for all of them.
Set the jtag_id variable to the device ID (X) of the card you want to program:
set jtag_id X
Then run the following commands to program the card:
spi::program_bitstream config2 bitstream_page0.flash 1 -offset 0 -device_id $jtag_id -switch30
spi::program_bitstream config2 bitstream.flash 4 -offset 4096 -device_id $jtag_id -switch30
Now power-cycle the machine and the card should be programmed. A reboot is not sufficient.
CAIMAN-ASR server release bundle
Release name: caiman-asr-server-<version>.run
This release bundle contains all the software needed to run the Myrtle.ai CAIMAN-ASR server in a production environment. This includes the server docker image, a simple Python client, and scripts to start and stop the server. Additionally, it contains a script to compile a hardware checkpoint into a CAIMAN-ASR checkpoint. Three model architectures are supported:
testingbaselarge
The testing config is not recommended for production use.
See details here
The CAIMAN-ASR server supports two backends: CPU and FPGA. The CPU backend is not real time, but
can be useful for testing on a machine without an Achronix Speedster7t PCIe card
installed. The FPGA backend is able to support 2000 concurrent transcription
streams per card with the base model and 800 with the large model.
Quick start: CPU backend
-
Load the CAIMAN-ASR server docker image:
docker load -i docker-asr-server.tgz -
Start the CAIMAN-ASR server with the hardware checkpoint:
./start_asr_server.sh --rnnt-checkpoint compile-model-checkpoint/hardware_checkpoint.testing.example.pt --cpu-backend --no-beam-decoder
This example turns off beam decoding because it's unsupported by the CPU backend. If you want to calculate WER using beam search without an FPGA, please use the ML training repository as described here.
-
Once the server prints "Server started on port 3030", you can start the simple client. This will send a librispeech example wav to the CAIMAN-ASR server and print the transcription:
cd simple_client ./build.sh # only needed once to install dependencies ./run.sh cd ..To detach from the running docker container without killing it, use ctrl+p followed by ctrl+q.
-
Stop the CAIMAN-ASR server(s)
./kill_asr_servers.sh
Quick start: FPGA backend
If you are setting up the server from scratch you will need to flash the Achronix Speedster7t FPGA with the provided bitstream. If you have a demo system provided by Myrtle.ai or Achronix, the bitstream will already be flashed. See the Programming the card section for instructions on flashing the FPGA before continuing.
Unlike with the CPU backend, you will need to compile the hardware checkpoint into a CAIMAN-ASR checkpoint (step 2 below). For more details on this process, see the Compiling weights section.
-
Load the CAIMAN-ASR server docker image
docker load -i docker-asr-server.tgz -
Compile an example hardware checkpoint to a CAIMAN-ASR checkpoint
cd compile-model-checkpoint ./build_docker.sh ./run_docker.sh hardware_checkpoint.testing.example.pt caiman_asr_checkpoint.testing.example.pt cd .. -
Start the CAIMAN-ASR server with the CAIMAN-ASR checkpoint (use
--card-id 1to use the second card).--license-dirshould point to the directory containing your license files. See the Licensing section for more information../start_asr_server.sh --rnnt-checkpoint compile-model-checkpoint/caiman_asr_checkpoint.testing.example.pt --license-dir "./licenses/" --card-id 0To detach from the running docker container without killing it, use ctrl+p followed by ctrl+q.
-
Once the server prints "Server started on port 3030", you can start the simple client. This will send a librispeech example wav to the CAIMAN-ASR server and print the transcription:
cd simple_client ./build.sh # only needed once to install dependencies ./run.sh cd .. -
Stop the CAIMAN-ASR server(s)
./kill_asr_servers.sh
State resets
State resets improve the word error rate of the CAIMAN-ASR server on long utterances by resetting the hidden state of the model after a fixed duration.
This improves the accuracy but reduces the number of real-time streams that can be supported by about 25%.
If your audio is mostly short utterances (less than 60s), you can disable state resets to increase the number of real-time streams that can be supported.
State resets are switched on by default, but they can be disabled by passing the --no-state-resets flag to the ./start_server script.
More information about state resets can be found here.
Beam decoding
Beam decoding improves WER but reduces RTS;
see here for more details.
Beam search is switched on by default,
but it can be disabled by passing the --no-beam-decoder flag.
More information about beam decoding is here.
When decoding with beam search, the server will return two types of response, either 'partial' or 'final'. For more details, see here.
Connecting to the websocket API
The websocket endpoint is at ws://localhost:3030.
See Websocket API for full documentation of the websocket interface.
The code in simple_client/simple_client.py is a simple example of how to connect to the CAIMAN-ASR server using the websocket API.
The code snippets below are taken from this file, and demonstrate how to connect to the server in Python.
Initially the client needs to open a websocket connection to the server.
ws = websocket.WebSocket()
ws.connect(
"ws://localhost:3030/asr/v0.1/stream?content_type=audio/x-raw;format=S16LE;channels=1;rate=16000"
)
Then the client can send audio data to the server.
for i in range(0, len(samples), samples_per_frame):
payload = samples[i : i + samples_per_frame].tobytes()
ws.send(payload, websocket.ABNF.OPCODE_BINARY)
The client can receive the server's response on the same websocket connection. Sending and receiving can be interleaved.
msg = ws.recv()
print(json.loads(msg)["alternatives"][0]["transcript"], end="", flush=True)
When the audio stream is finished the client should send a blank frame to the server to signal the end of the stream.
ws.send("", websocket.ABNF.OPCODE_BINARY)
The server will then send the final transcriptions and close the connection.
The server consumes audio in 60ms frames, so for optimal latency the client should send audio in 60ms frames. If the client sends audio in smaller chunks the server will wait for a complete frame before processing it. If the client sends audio in larger chunks there will be a latency penalty as the server waits for the next frame to arrive.
A more advanced client example in Rust is provided in caiman-asr-client; see Testing inference performance for more information.
Convert PyTorch checkpoints to CAIMAN-ASR programs
Release name: caiman-asr-server-<version>/compile-model-checkpoint
This is a packaged version of the CAIMAN-ASR model compiler, which can be used to convert PyTorch checkpoints to CAIMAN-ASR checkpoints. The CAIMAN-ASR checkpoint contains the instructions for the model to enable CAIMAN-ASR acceleration. These instructions depend on the weights of the model, so when the model is changed, the CAIMAN-ASR checkpoint needs to be recompiled.
The flow to deploy a trained CAIMAN-ASR model is:
- Convert the training checkpoint to a hardware checkpoint following the steps in the Exporting a checkpoint section. Hardware checkpoints can be used with the CAIMAN-ASR server directly if you specify
--cpu-backend. - Convert the hardware checkpoint to a CAIMAN-ASR checkpoint with the
compile-model.pyscript in this directory. CAIMAN-ASR checkpoints can be used with the CAIMAN-ASR server with either of the CPU or FPGA backends.
Usage
The program can be run with docker or directly if you install the dependencies.
Docker
Install docker and run the following commands:
./build_docker.sh
./run_docker.sh path/to/hardware-checkpoint.pt output/path/to/caiman-asr-checkpoint.pt
Without docker
Ensure that you are using Ubuntu 20.04 - there are libraries required by the CAIMAN-ASR assembler that may not be present on other distributions.
pip3 install -r ./requirements.txt
./compile-model.py \
--hardware-checkpoint path/to/hardware-checkpoint.pt \
--mau-checkpoint output/path/to/caiman-asr-checkpoint.pt
These commands should be executed in the compile-model-checkpoint directory
otherwise the python script won't be able to find the mau_model_compiler binary.
WebSocket API for Streaming Transcription
Connecting
To start a new stream, the connection must first be set up. A WebSocket
connection starts with a HTTP GET request with header fields Upgrade: websocket and Connection: Upgrade as per
RFC6455.
GET /asr/v0.1/stream HTTP/1.1
Host: api.myrtle.ai
Upgrade: websocket
Connection: Upgrade
Sec-WebSocket-Key: dGhlIHNhbXBsZSBub25jZQ==
Sec-WebSocket-Protocol: stream.asr.api.myrtle.ai
Sec-WebSocket-Version: 13
If all is well, the server will respond in the affirmative.
HTTP/1.1 101 Switching Protocols
Upgrade: websocket
Connection: Upgrade
Sec-WebSocket-Accept: s3pPLMBiTxaQ9kYGzzhZRbK+xOo=
Sec-WebSocket-Protocol: stream.asr.api.myrtle.ai
The server will return HTTP/1.1 400 Bad Request if the request is invalid.
Request Parameters
Parameters are query-encoded in the request URL.
Content Type
| Parameter | Required | Default |
|---|---|---|
content_type | Yes | - |
Requests can specify the audio format with the content_type parameter. If the content type is not
specified then the server will attempt to infer it. Currently only audio/x-raw is supported.
Supported content types are:
audio/x-raw: Unstructured and uncompressed raw audio data. If raw audio is used then additional parameters must be provided by adding:format: The format of audio samples. Only S16LE is currently supportedrate: The sample rate of the audio. Only 16000 is currently supportedchannels: The number of channels. Only 1 channel is currently supported
As a query parameter, this would look like:
content_type=audio/x-raw;format=S16LE;channels=1;rate=16000
Model Identifier
| Parameter | Required | Default |
|---|---|---|
model | No | "general" |
Requests can specify a transcription model identifier.
Model Version
| Parameter | Required | Default |
|---|---|---|
version | No | "latest" |
Requests can specify the transcription model version. Can be "latest" or a specific version id.
Model Language
| Parameter | Required | Default |
|---|---|---|
lang | No | "en" |
The BCP47 language tag for the speech in the audio.
Max Number of Alternatives
| Parameter | Required | Default |
|---|---|---|
alternatives | No | 1 |
The maximum number of alternative transcriptions to provide.
Supported Models
| Model id | Version | Supported Languages |
|---|---|---|
| general | v1 | en |
Request Frames
For audio/x-raw audio, raw audio samples in the format specified in the
format parameter should be sent in WebSocket Binary frames without padding.
Frames can be any length greater than zero.
A WebSocket Binary frame of length zero is treated as an end-of-stream (EOS) message.
Response Frames
Response frames are sent as WebSocket Text frames containing JSON.
{
"start": 0.0,
"end": 2.0,
"is_provisional": false,
"alternatives": [
{
"transcript": "hello world",
"confidence": 1.0
}
]
}
API during greedy decoding
start: The start time of the transcribed interval in secondsend: The end time of the transcribed interval in secondsis_provisional: Always false for greedy decoding (but can be true for beam decoding)alternatives: Contains at most one alternative for greedy decoding (but can be more for beam decoding)transcript: The model predictions for this audio interval. Not cumulative, so you can get the full transcript by concatenating all thetranscriptfieldsconfidence: Currently unused
API during beam decoding
When decoding with a beam search, the server will return two types of response, either 'partial' or 'final' where:
- Partial responses are hypotheses that are provisional and may be removed or updated in future frames
- Final responses are hypotheses that are complete and will not change in future frames
It is recommended to use partials for low-latency streaming applications and finals for the ultimate transcription output. If latency is not a concern you can ignore the partials and concatenate the finals.
Detection of finals is done by checking beam hypotheses for a shared prefix. Typically it takes no more than 1.5 seconds to get finals (and often they are much faster) but it is possible that two similar hypotheses with similar scores are maintained in the beam for a long period of time. As such it is always recommended to use partials with state-resets enabled (see state-reset docs).
When running the asr server, partial responses are marked with "is_provisional": true and finals with "is_provisional": false and partials can be one of the many "alternatives: [...]".
During a partial response,
the alternatives are ordered from most confident to least.
At each frame,
it's guaranteed that the server will send
a final or partial response, and perhaps both, as explained
here:
* Every frame other than the last one will have partials and may also have a final
* The last frame will not have partials and may have a final if there is outstanding
text.
Closing the Connection
The client should not close the WebSocket connection, it should send an EOS message and wait for a WebSocket Close frame from the server. Closing the connection before receivng a WebSocket Close frame from the server may cause transcription results to be dropped.
An end-of-stream (EOS) message can be sent by sending a zero-length binary frame.
Errors
If an error occurs, the server will send a WebSocket Close frame, with error details in the body.
| Error Code | Details |
|---|---|
| 400 | Invalid parameters passed. |
| 503 | Maximum number of simultaneous connections reached. |
Testing Inference Performance
Release name: caiman-asr-client-<version>.run
This is a simple client for testing and reporting the latency of the CAIMAN-ASR server. It spins up a configurable number of concurrent connections that each run a stream in realtime.
Running
A pre-compiled binary called caiman-asr-client is provided. The client documentation can be viewed with the
--help flag.
$ ./caiman-asr-client --help
This is a simple client for evaluation of the CAIMAN-ASR server.
It drives multiple concurrent real-time audio channels providing latency figures and transcriptions. In default mode, it spawns a single channel for each input audio file.
Usage: caiman-asr-client [OPTIONS] <INPUTS>...
Options:
--perpetual
Every channel drives multiple utterances in a loop. Each channel will only print a report for the first completed utterance
--concurrent-connections <CONCURRENT_CONNECTIONS>
If present, drive <CONCURRENT_CONNECTIONS> connections concurrently. If there are more connections than audio files, connections will wrap over the dataset
-h, --help
Print help (see a summary with '-h')
WebSocket connection:
--host <HOST>
The host to connect to. Note that when connecting to a remote host, sufficient network bandwidth is required when driving many connections
[default: localhost]
--port <PORT>
Port that the CAIMAN-ASR server is listening on
[default: 3030]
--connect-timeout <CONNECT_TIMEOUT>
The number of seconds to wait for the server to accept connections
[default: 15]
--quiet
Suppress printing of transcriptions
Audio:
<INPUTS>...
The input wav files. The audio is required to be 16 kHz S16LE single channel wav
If you want to run it with many wav files you can use find to list all the wav files in a directory (this
will hit a command line limit if you have too many):
./caiman-asr-client $(find /path/to/wav -name '*.wav') --concurrent-connections 1000 --perpetual --quiet
Building
If you want to build the client yourself you need the rust compiler. See https://www.rust-lang.org/tools/install
Once installed you can compile and run it with
$ cargo run --release -- my_audio.wav --perpetual --concurrent-connections 1000
If you want the executable you can run
$ cargo build --release
and the executable will be in target/release/caiman-asr-client.
Latency
The CAIMAN-ASR server provides a response for every 60 ms of audio input, even if that response has no transcription. We can use this to calculate the latency from sending the audio to getting back the associated response.
To prevent each connection sending audio at the same time, the client waits a random length of time (within the frame duration) before starting each connection. This provides a better model of real operation where the clients would be connecting independently.
Demonstrating live transcription using a local microphone
The live demo client is found in the inference/live_demo_client directory.
This script connects to a running CAIMAN-ASR server and streams audio from your microphone to the server for low-latency transcription.
Step 1: Set up the CAIMAN-ASR server
Follow the instructions provided in Inference Flow to set up the ASR server.
Step 2: Set up the client
Locally, install dependencies:
sudo apt install portaudio19-dev python3-dev # dependencies of PyAudio
pip install pyaudio websocket-client
(Or if you are a Nix user, nix develop will install those)
Then run the client with ./live_client.py --host <host> --port <port> where <host> and <port> are the host and port of the ASR server respectively.
Troubleshooting
If the client raises OSError: [Errno -9997] Invalid sample rate, you may need to
use a different audio input device:
- Run
./print_input_devices.pyto list available input devices - Try each device using (for example)
./live_client.py --input_device 5
Hardware requirements
The following is a guide to the hardware requirements for the CAIMAN-ASR server.
Host requirements
The CAIMAN-ASR server requires a host machine with the following specifications:
- Four CPU cores per VectorPath card
- 4 GB of memory per VectorPath card
- 100 GB of storage
- Ubuntu 22.04 LTS (recommended)
Bandwidth
The server requies 500 Mbits/s of bandwidth per 1000 streams. For example, 2000 streams would require 1 Gbit/s of bandwidth.
The bandwidth is dependent on the number of streams and not the number of cards (one card can handle 2000 streams with the base model or 800 streams with the large model).
This figure has some headroom built in; the measured value on a reliable connection is 700 Mbits/s for 2000 streams.
CAIMAN-ASR demo
Release name: caiman-asr-demo-<version>.run
This software bundle is used for demonstrating the server.
It includes the asr server and a web interface which shows the live transcriptions and latency of the server.
This is not the right software to use for production installations; the docker container doesn't expose the server port so external clients cannot connect to it.
For production installations, use the caiman-asr-server-<version>.run release. See instructions in the CAIMAN-ASR server section.
Running the CAIMAN-ASR Demo Server
If you are setting up the server from scratch you will need to flash the Achronix Speedster7t FPGA with the provided bitstream. If you have a demo system provided by Myrtle.ai or Achronix, the bitstream will already be flashed. See the Programming the card section for instructions on flashing the FPGA.
-
Load the CAIMAN-ASR Demo Server Docker image:
docker load -i docker-asr-demo.tgz -
Start the server with:
./start_server <license directory> [card index]...where
<license directory>is the path to the directory containing your Myrtle.ai licence and[card index]is an optional integer list argument specifying which card indices to use, e.g.0 1 2 3. The default is 0.The demo GUI webpage will then be served at http://localhost.
The latency may be much higher than usual during start-up. Refreshing the webpage will reset the scale on the latency chart.
To shut down the server you can use ctrl+c in the terminal where the server is running.
Alternatively, run the following:
./kill_server