Key Features
CAIMAN-ASR enables at-scale automatic speech recognition (ASR), supporting up to 2000 real-time streams per accelerator card.
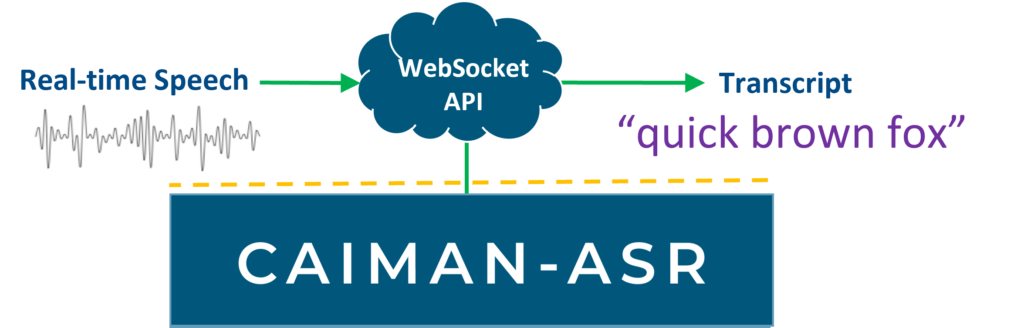
Lowest end-to-end latency
CAIMAN-ASR leverages the parallel processing advantages of Achronix’s Speedster7t® FPGA, the power behind the accelerator cards, to achieve extremely low latency inference. This enables NLP workloads to be performed in a human-like response time for end-to-end conversational AI.
Simple to integrate into existing systems
CAIMAN-ASR's Websocket API can be easily connected to your service.
Scale up rapidly & easily
CAIMAN-ASR runs on industry-standard PCIe accelerator cards, enabling existing racks to be upgraded quickly for up to 20x greater call capacity. The VectorPath® S7t-VG6 accelerator card from BittWare is available off-the-shelf today.
Efficient inference, at scale
CAIMAN-ASR uses as much as 90% less energy to process the same number of real-time streams as an unaccelerated solution, significantly reducing energy costs and enhancing ESG (environmental, social, and governance) credentials.
Streaming transcription
CAIMAN-ASR is provided pre-trained for English language transcription. For applications requiring specialist vocabularies or alternative languages, the neural model can easily be retrained with customers’ own bespoke datasets using the ML framework PyTorch.
Model Configurations
The solution supports two model configurations:
| Model | Parameters | Realtime streams (RTS) | RTS with state resets enabled | p99 latency at max RTS | p99 latency at RTS=32 |
|---|---|---|---|---|---|
base | 85M | 2000 | 1750 | 70 ms | 15 ms |
large | 196M | 800 | 600 | 70 ms | 15 ms |
where:
- Realtime streams (RTS) is the number of concurrent streams that can be serviced by a single accelerator using default settings
- p99 latency is the 99th-percentile latency to process a single 60 ms audio frame and return any predictions. Note that latency increases with the number of concurrent streams.
- state resets is a technique that improves the accuracy on long utterances (over 60s) by resetting the model's hidden state after a fixed duration. This reduces the number of real-time streams that can be supported by around 25%, but for use-cases involving only short utterances it can be switched off.
The solution scales linearly up to 8 accelerators, and a single server has been measured to support 16000 RTS with the base model.
Word Error Rates (WERs)
The solution has the following WERs when trained on the open-source data described below:
| Model | MLS | LibriSpeech-dev-clean | LibriSpeech-dev-other | Earnings21* |
|---|---|---|---|---|
base | 9.36%† | 3.01%† | 8.14%† | 17.02% |
large | 7.70% | 2.53% | 6.90% | 15.57% |
These WERs are for streaming scenarios without additional forward context. Both configurations have a frame size of 60ms, so, for a given segment of audio, the model sees between 0 and 60ms of future context before making predictions.
Notes
-
The MLS, LibriSpeech-dev-clean and LibriSpeech-dev-other WERs are for a model trained on the 50k hrs dataset while the Earnings21 WERs are for a model trained on the 10k hrs dataset.
-
*None of Myrtle.ai's training data includes near-field unscripted utterances or financial terminology so the Earnings21 benchmark is out-of-domain for these systems.
-
†These WERs were not updated for the latest release. The provided values are from version v1.6.0.